

前言
要说最近十年最流行的互联网名词,“大数据”绝对算一个。我们生活在这个信息时代,无时不刻不在产生数据。据统计,1992 年,全人类每天只产生 100GB 数据;时至今日,全球 70 亿人,平均每人每天产生的数据高达 1.5GB。面对海量的数据,怎样采集、加工、存储,并将数据转化为价值,成为了各大厂商乃至国家都在研究的重点方向。

何谓大数据?——大数据的概念
大数据有多“大”?
所谓大数据,顾名思义就是很多很多的数据,这个“很多很多”到底是多少呢?
其实这个“多”并没有一个固定的数值。我个人理解,这里的“多”,也就是大数据的“大”是一个相对的概念,指的是对于现如今常规的技术手段难以进行处理的数据量,这个量会随着技术的发展不断增大。这是大数据的的一个特定,数据量大。这也契合了大数据的概念:
大数据(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。(来自百度百科)
大数据都有哪些数据?
大数据所包含的数据类型并不局限于传统数据库中的结构化数据,还有有xml、json文本、日志等半结构化数据,甚至还有音视频、图片这种非结构化数据,可谓包罗万象。这是大数据的第二个特定,数据类型多样。
数据都有价值吗?
前面我们已经知道,大数据包含海量的数据,并且数据类型多种多样,但这么多的数据都有价值吗?当然不是,面对产生的不计其数的数据,往往只有少量的数据才具有价值,比如我们做系统监控,可能只有系统出现异常那几秒钟的异常数据才更有价值。这是大数据的第三个特点,价值密度低。这就要求我们要有强大的数据抽取能力。
大数据能带来什么?——大数据的价值与应用
正如概念里指出,大数据是要通过对巨量的数据进行处理,从而转化为更具价值的数据。那么大数据究竟能提供什么价值,又是怎样指导我们的生产与生活的呢?
在探究大数据究竟能带给我们什么之前,我们这里先看一个“烂大街”的小故事:

传说,在上世纪90年代,美国的沃尔玛超市会将啤酒与尿不湿这两种看似毫不相干的商品放在相邻货架上售卖,并且商品的销量有了显著的提升。这背后的原因在于,售货员通过对账单进行分析发现,出来买尿不湿的人中,多数为父亲,而且很多父亲在购买尿不湿之后如果同时看到,很大概率会顺手买几瓶啤酒。所以,将尿不湿与啤酒一同摆放,能够促进啤酒的销量。
这个小故事可谓数据分析营销案例的鼻祖,看似简单的案例,其中数据分析的思路放到现在也不过时,就像我们网购时的“猜你喜欢”,刷短视频时的“相关推荐”,都是根据我们平时浏览商品、视频产生的数据加以分析得到的结果。
像上面提到的商品推荐在大数据领域可以归类于推荐系统。推荐系统依赖于算法模型,而模型需要大量的数据来进行训练,数据量越大,系统推荐的精准性就越强。
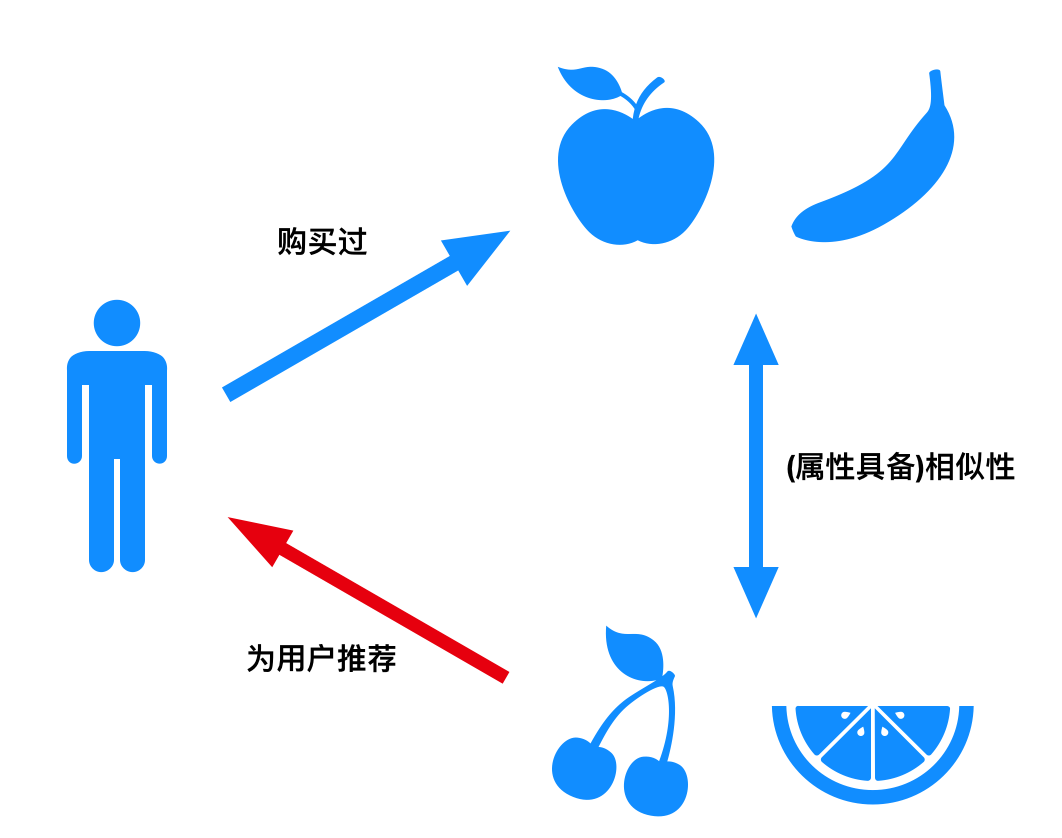
除了推荐系统,大数据在我们生活中的应用还有很多场景。比如大家都下载了国家反诈骗APP,那反诈APP是怎样识别诈骗信息的呢?同样也是通过大数据系统,一方面,系统可以通过对诈骗电话、短信进行分析,通过关键词识别到风险,再有大量的数据支撑,系统能够更加精准的识别到诈骗风险。
除了生活的中的应用,大数据在工业生产中也发挥着重要的作用。比如工业设备的指标监控,对于异常的指标进行报警,并可以根据日常的指标自动调整报警阈值。比如数据看板,对业务系统各种指标进行汇总统计与分析,为业务系统精细化、智能化运营提供数据支撑。
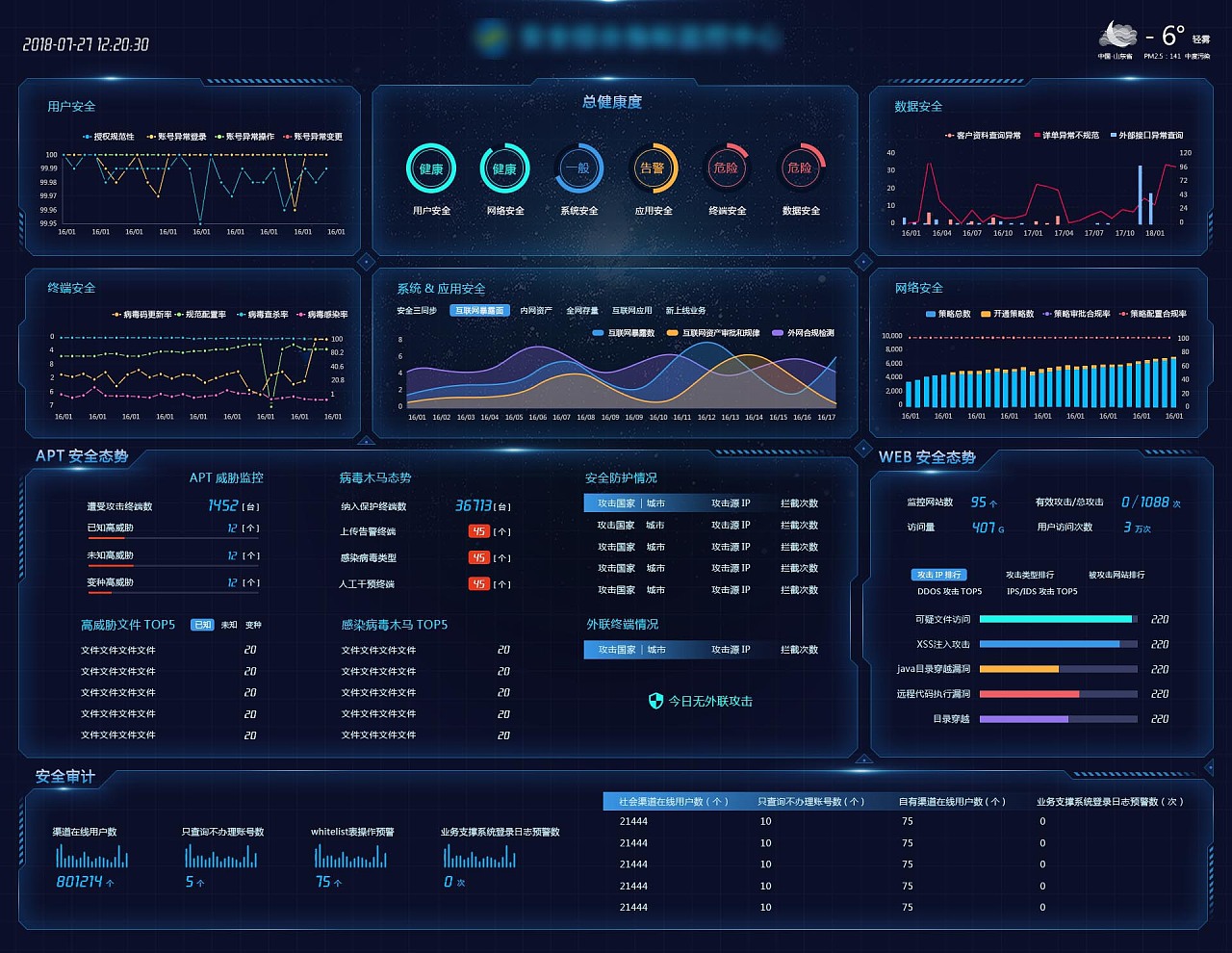
拿我们自身举例,我们目前对网关、数据库、业务系统等系统的运行日志进行监控,通过大数据系统进行数据的抽取、转换、规则匹配,对系统风险进行实时告警,帮助开发、运维人员快速定位、及时处理问题,将系统风险最小化。
其实大数据的应用以及渗透在我们生活的方方面面,我以上列举的也只是冰山一角,更多的使用场景也等待着大家去发掘。
怎样使用大数据?——大数据常见技术与其使用场景
通过前面的介绍,我们已经知道了大数据是什么,大数据怎么样,接下来我们简单介绍一下大数据所涉及的技术。
数据仓库
谈大数据,数据仓库是个绕不过的话题。可以说数仓是大数据的基础,尤其在早期的离线计算领域,数仓是必不可少的系统。
数仓的概念
首先我们先明确一个概念,数据仓库是存储数据的仓库,面向主题,主要对数据进行分析处理,保存的数据都是之前已存在的数据。
数据仓库有以下特点:
- 面向主题:决策的需求
- 集成性:将相同类型的数据融合在一起
- 非易失性:存储的都是已经发生的数据,不可更新
- 时变性:使用新的分析手段,对数据进行分析处理
数仓与数据库
看到这里很多人都会产生一个疑问,数仓与数据仓库的区别是什么?数据库也是存储数据的仓库,但数据库更多的面向业务系统,主要对数据增删改查,事务操作,用来捕获业务系统的数据;而数据仓库专用于数据分析,一般不支持实务操作,数据取决于外部系统,自己不产生数据。说到底数据库与数据仓库的区别就是OLTP与OLAP的区别。数据仓库的出现不会替代数据库,数据库是面向事务的,数据仓库是面向主题的。
OLTP:联机事务处理
OLAP:联机分析处理
数仓的架构
一般来说数仓可以分为三层:
-
ODS:原始数据层——存储原始数据,一般不需要额外定义
-
DW:数据仓库层——对原始数据进行清洗工作,将无用数据去除,将干净的数据存储起来,对数据进行分析处理
-
APP:数据展示层——将分析后的结果展示处理
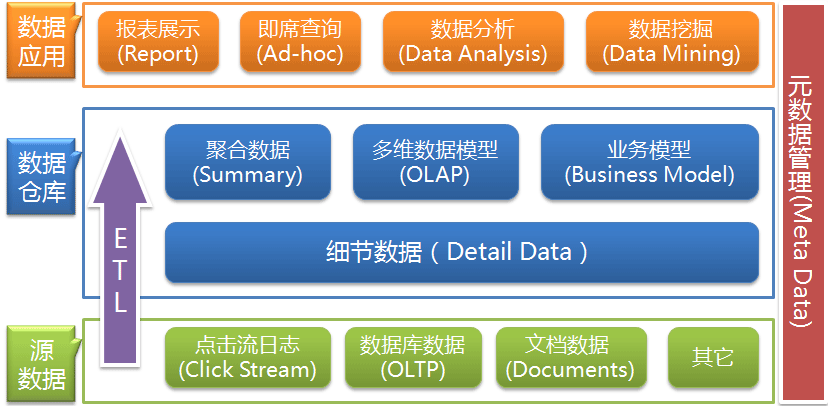
当然,数仓的层级在不同的企业中也有细节上的不同,比如在阿里的数仓体系中引入了DM数据集市层,比如dw层可以细分为dws明细层、dwa汇总层等,都是对数据仓库层进行进一步的补充与拓展。
数据仓库核心流程(ETL):
- E:抽取——将原始数据清洗后转换为干净的数据
- T:转换——对清洗后的数据进行分析处理
- L:装载——将得出的结论交给数据展示层进行展示操作
Hive

Apache Hive是基于Hadoop(大数据计算、存储引擎,下文中将讲到)的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
Hive将数据存储到HDFS(Hadoop的分布式文件系统,下文中将讲到)中,执行SQL的时候将SQL语句转换为MR(Hadoop的分布式计算框架,下文中将讲到)程序,提交给YARN(Hadoop的资源管理平台,下文中将讲到)平台,进行计算统计。
Hive是市面上流行的数仓管理工具,拥有良好的扩展性、延展性以及容错性,但由于本身依赖于Hadoop的MR进行计算,所以计算速度缓慢,适用于离线计算。后续市面上出现了很多性能更优秀的OLAP引擎,可以一定程度上代替Hive进行数据的计算,但Hive在时效性低、成本低的计算场景下,仍然是很不错的选择。
对于数仓在此我再补充一点,在我看来,数据仓库不是某一个软件也不是每一类软件,而是一种思想,一种数仓分层与建模的思想,我甚至见过一些规模较小的公司拿传统数据库做数仓,虽然不推荐这样,但如果数据量少,性能足够支撑,问题也不大。
Hadoop生态圈
作为开发者,无论是不是做大数据开发的,相信多少也都听说过Apache Hadoop的大名。Hadoop一定程度上可以说是大数据相关技术的基石。Hadoop来源于大数据计算的开创者Google在2003到2006年间发表了三篇论文:《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》。也正是这三篇论文开启了工业界的大数据时代。
Hadoop是市面上最主流的大数据计算、存储引擎,不仅自身拥有出色的计算、存储能力,其生态圈十分完善,以至于以后出现的新技术绝大多数也都会向Hadoop兼容。
Hadoop核心组件

Hadoop为什么在大数据行业中地位如此之高,我们看一下核心组件:
- Hadoop Common:分布式文件系统和通用I/O的组件与接口(序列化、Java RPC和持久化数据结构)。
- HDFS:Hadoop Distributed FileSystem(分布式文件系统):存储数据。
- MR:Hadoop MapReduce(分布式计算框架):分布式计算,计算数据。
- YARN:Hadoop YARN(分布式资源管理器):MapReduce任务在YARN上执行,由YARN来管理资源。
HBase

与上面提到的Hive一样,HBase也是依赖于Hadoop的数据系统。HBase是一个建立在HDFS之上,分布式、列式存储的NoSQL数据库,用于快速读/写大量数据。HBase来自于Google的《Bigtable》论文,拥有超大的数据吞吐性能,由于是列式存储,天然有利于数据的局和分析。
数据采集工具
Hadoop生态圈提供两款数据采集工具,分别是:
-
Sqoop
- Sqoop是SQLtoHadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。
-
Flume
- Flume是一个分布式、可靠、和高可用的海量日志聚合系统,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
Oozie
Oozie 是一个开源的工作流和协作服务引擎,基于 Apache Hadoop 的数据处理任务。Oozie 是可扩展的、可伸缩的面向数据的服务,运行在Hadoop 平台上。
Spark & Flink
之所以把Spark与Flink一起说,是因为他俩有很多相似之处。他们都是当下热门的数据处理引擎,他们都提供批处理与流处理能力,他们都提供完整的生态系统,他们都兼容HadoopYARN,他们都拥有十分优秀的计算性能。
Spark

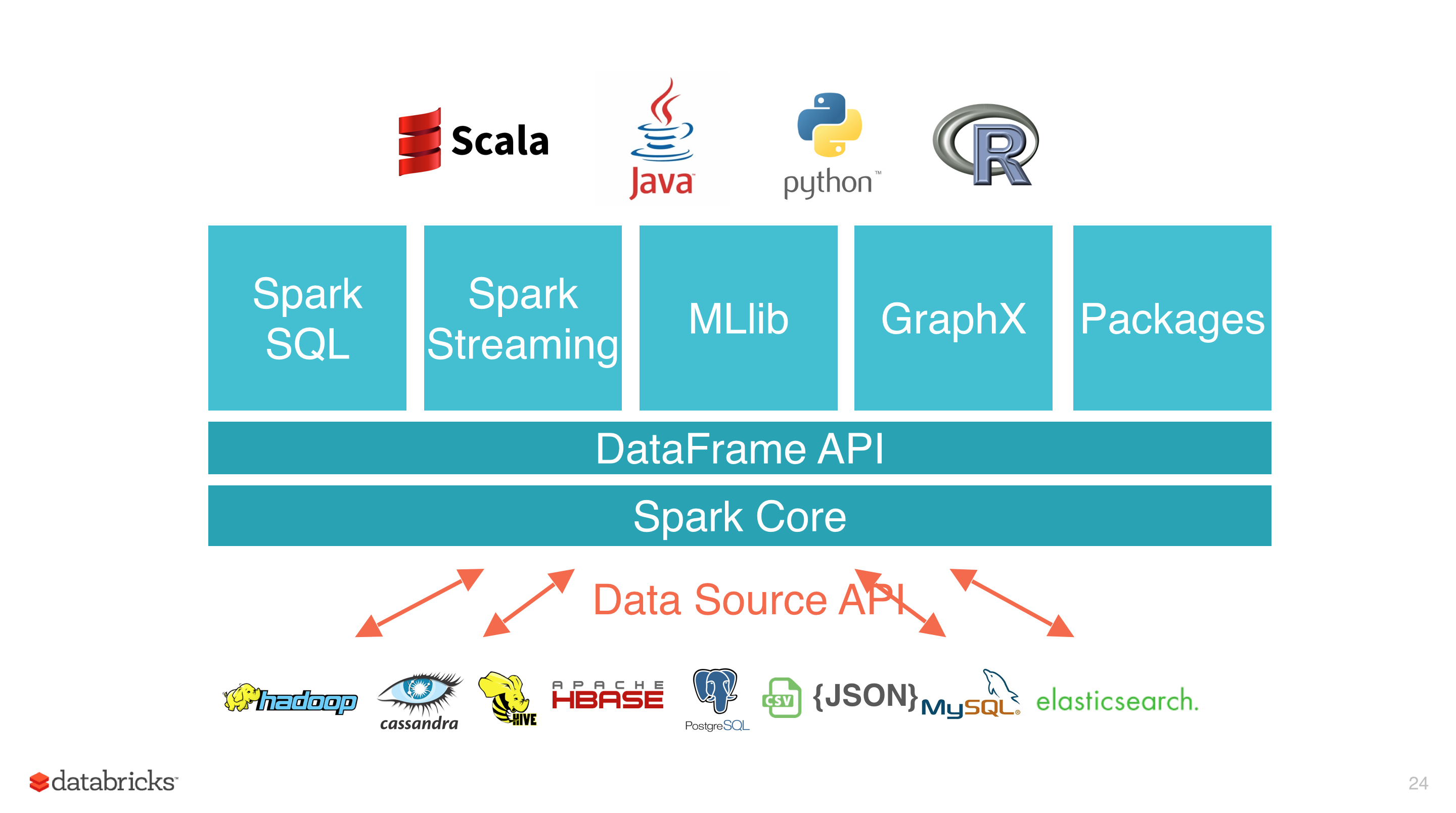
Apache Spark 是用于大规模数据处理的统一分析引擎。它提供 Java、Scala、Python 和 R 中的高级 API,以及支持通用执行图的优化引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的 Spark SQL、用于机器学习的 MLlib、用于图形处理的 GraphX,以及用于增量计算和流处理的结构化流。
Spark计算基于内存,除此之外,Spark还提供优秀的作业调度策略,这决定了它的计算效率要比MR高出几十倍。
Flink

Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。Flink提供Java、Scala、Python等API接口,同事提供SQLAPI。
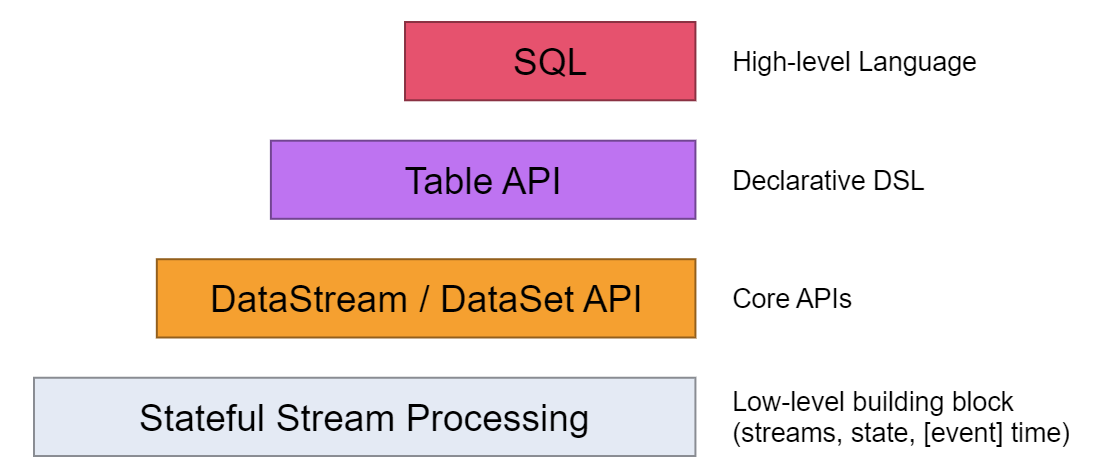
Flink提供了四层API以供调用,从下到上分别是有状态实时流处理API、Core APIs、Table API、SQL,每一层都对上一层进行了一次抽象。
正如官网给出的定义,Flink的所有计算都是基于数据流的,因此Flink对实时计算拥有天生的优势。对于离线计算,Flink将离线数据视为很长的流,提供与流计算统一的API进行数据处理。
Flink要比Spark的出现稍晚一些,因此也在Spark身上吸取到很多经验,Spark在后起之秀Flink崛起之后也取长补短不断完善自身的计算的模型,二者可谓相辅相成。业界经常拿Spark与Flink进行比较,但在我看来,技术没有最好,只有更合适,二者都是十分优秀的计算框架,使计算脱离了Hadoop的MR,极大的提升了数据计算的速度。