

背景
系统架构
我们公司用Flink来做实时流处理,并使用CEP组件进行实时风控,对前置机日志进行异常监控。公司系统中共有7台Nginx前置机,其中4台属于A组,另3台属于B组,我们使用Filebeat采集了各台前置机日志,统一发送给Logstash进行解析,解析后的数据一面写入ES做成流量看板,一面发送到Kafka,对接到Flink进行数据处理,对于异常流量进行告警。系统好好的运行了半年多了,一直还挺稳定的。
异常出现
最近几天系统收到几次异常告警都来着B组前置机的流量,我们还纳闷,明明A组的流量更多一些,最近的告警却都来自B组,难道A组最近很稳定?我们试着模拟了恶意的请求到A组前置机,哎?我这么大个一告警呢??为了做对照,我们以同样的方式请求了B组前置机,果然告警出来了。为什么为什么为什么,日志明明都写到一起了,为什么只有B组的告警生效了?
排查过程
程序处理❌
我们首先想到的是Flink程序是不是有问题,但这个怀疑很快被清除了。
首先这个服务最近都没动过,如果程序有问题的话那应该早就暴露出来了。
其次是7台前置机的日志都汇总到了同一个kafka topic中,随后在Flink程序中也都是以同一个stream进行的处理,如果有问题那应该都会受影响,不存在一部分数据出现问题的现象。
前置机日志❌
如果数据汇总之后没问题,那么在汇总之前会不会有问题呢?比如前置机日志是不是丢失了?
我们消费了一下汇总后的kafka topic,通过观察,7台前置机的日志都是存在的,而且数据量也都比较平均,初步排除日志丢失的问题。
那会不会是某些前置机日志格式发生变化,在Flink中解析JSON字符串时发生了异常?
通过对比,7台前置机的日志不能说差不多,只能说是一毛一样。所以日志格式问题看起来也排除了。
等等,日志格式没问题,但是日志本身有没有问题呢?
前置机时间不同步⭕
我们使用同一个ip连续请求了两组前置机,得到如下两条日志,
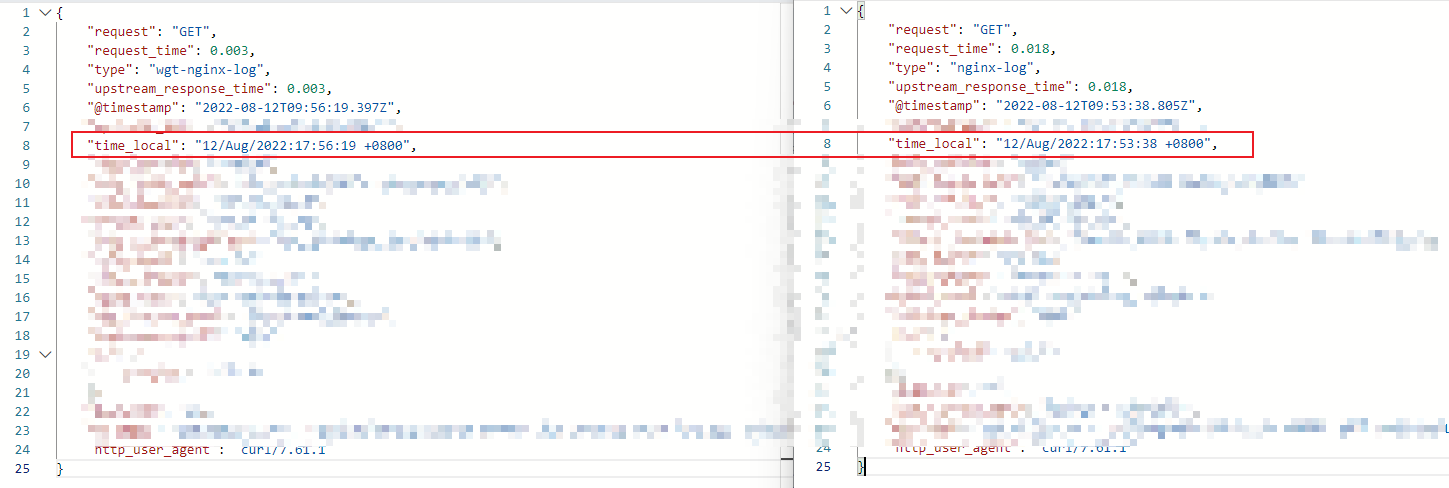
发现问题没有,两条连续的请求,请求时间竟然差了将近3分钟!
通过运维同事排查,我们发现,AB两组前置机的NTP对时服务不同,B组前置机的NTP服务最近出问题了,导致B组3台前置机本地时间要比标准时间快了2分多钟。
Flink Watermark受影响
不要小看这2分钟,这2分钟对Nginx影响不大,可对Flink可就影响太大了。我们都知道,Flink是流式计算引擎,时间是Flink实时计算中重要的属性。
Flink Watermark简介
Flink为了处理乱序数据,提供了Watermark(水位线)机制,简单说就是可以处理一定时间的迟到数据。比如说我设置了水位线的延迟时间为1分钟,系统可以接收当前最大时间向前1分钟之内的迟到数据,一分钟之前的数据便视为过期数据,不再处理。
为了让数据统计更精确,我们的系统中使用事件时间,时间采用的是nginx日志中的time_local字段转化后得到的时间戳,为了处理乱序数据,水位线延迟时间设置为了30s,也就是说能够处理30s之内的延迟数据。
但是我们现在的数据流中有一部分数据要比其他数据快了2分多钟,当这部分超前数据到达系统时,系统的水位线已经根据这部分超前数据进行重新划定,比如17:36:30的数据到达系统,根据水位线的划定公式watermark = maxEventTime - 延迟时间,此时水位线为17:36:00,也就是说早于17:36:00的数据都将被视为过期数据。但对于另外一些正常时间的数据,此时时间可能只是17:34:00,明明是正确的数据,却被当做过期数据无情抛弃。
总结一下就是,由于B组前置机的本地时间快了2分多钟,所以B组前置机的日志中的事件时间快了2分钟,导致Flink中的水位线过高,以至于A组前置机产生的正常时间的日志被过期了。
解决方法
解决方法也很简单,把B组前置机3台机器的时钟同步调整好,数据正常,监控恢复。
后记
此次问题不大,引起问题的原因也是挺让人哭笑不得的。但我认为这个问题非常典型,可以很好的帮我们理解Flink中Watermark机制的的原理与作用。在学习Flink时一直对watermark这一概念不是特别的理解,通过对这次问题的排查与总结,算是彻底明白了,也算是一种收获。