

Flume的定义
大数据要做什么?
大数据要做的就是三件事:数据的采集、数据的存储、数据的计算。数据的存储与数据的计算都要在数据采集的基础上进行,所以数据采集是大数据要做的第一件事,重要性不言而喻。
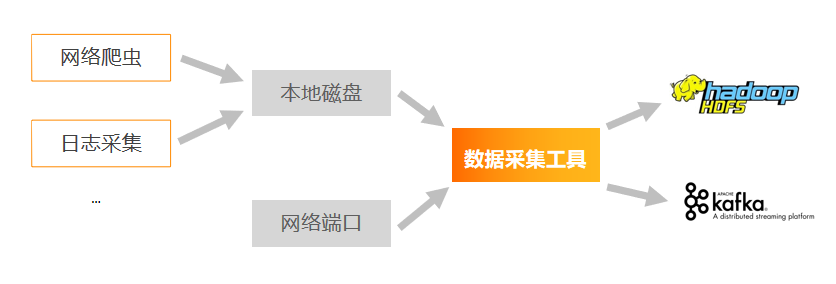
为什么需要数据采集工具?
那么数据是怎么采集的呢?通过学习我们知道,数据可以来自于网络爬虫、日志采集等等,这些日志往往存储在主机的本地磁盘中。如果我们想把这些数据写入到HDFS中,最基础的方法我们可以使用hdfs的put命令,上传本地文件。使用这种方法,每次上传的数据是全量的,并且不可能一直put。而且,如果我们对接的是实时计算系统,上述方式的效率极低,不能满足实时计算的数据采集效率。所以我们需要一种数据采集工具,可以实时帮我们监听本地文件,如果有新数据,就帮我们进行上传。
Flume的定义
Flume 是一种分布式、可靠、可用的服务,用于高效收集、聚合和移动大量日志数据。它具有基于流式数据流的简单灵活的体系结构。它具有可调节的可靠性机制和许多故障转移和恢复机制,具有健壮性和容错性。它使用允许在线分析应用程序的简单可扩展数据模型。

Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
Flume官网初体验

用户文档
官网文档十分详细,后续我们对Flume的使用与开发中遇到的大多数问题都可以通过查看文档解决。
Flume组成
通过前面的学习,我们知道个Flume是什么,接下来我们要探究Flume内部的组成。
Flume的基础架构
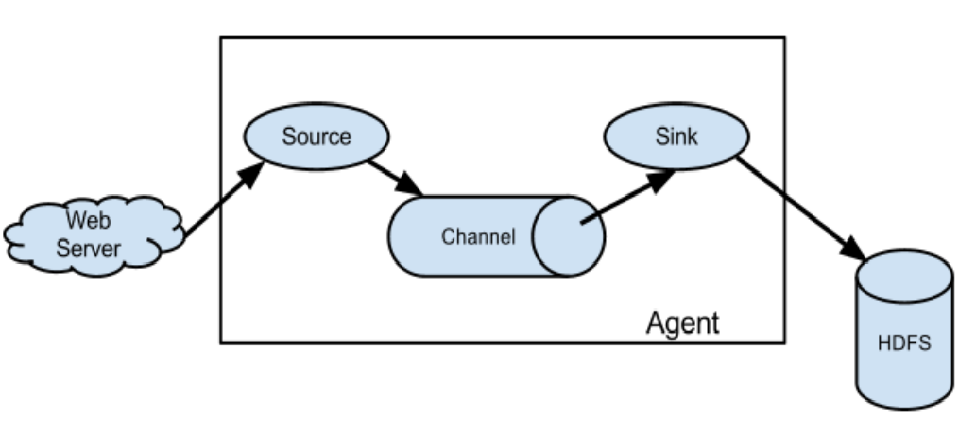
从图中我们可以看到,Flume架构很简单,我们把每一个Flume节点称为一个agent,agent中主要有三个组件,分别是Source、channel、sink。
Event
我们把数据传输的最小单位称为Event,一个event中有header和body组成,与http请求类似。Header中存放event的属性信息,以key-value的形式存储,body中存放数据,以字节数组的形式存储。

刚才我们讲到,agent中的三个组件分别是Source、channel、sink,顾名思义,他们分别数据的接收、传输和下沉。
Source
Source负责接收各种类型的日志文件,比如:
-
Avro Source:监听AVRO端口来接受来自外部AVRO客户端的事件流。另外也可以接受通过flume提供的Avro客户端发送的日志信息。
-
Exec source:适用于监控一个实时追加的文件,不能实现断点续传。
-
Spooling Directory Source:适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步。
-
Taildir Source:适合用于监听多个实时追加的文件,并且能够实现断点续传。
-
NetCat Source:一个NetCat Source用来监听一个指定端口,并将接收到的数据的每一行转换为一个事件。
-
HTTP Source:接受HTTP的GET和POST请求作为Flume的事件。
-
Kafka Source:Kafka Source 是一个 Apache Kafka 消费者,它从 Kafka 主题中读取消息。
Sink
Sink负责数据的下沉,就是将Flume Agent中的数据写入到指定位置,往往是用来写入HDFS。出此之外Sink还支持logger(日志)、avro(通常用来串联其他Flume)、file(写到文件)、HBASE、kafka等目的地。
Channel
Channel是在source与sink之间的缓冲区,设置缓冲区的目的是为了在sink与source速率不允许时对数据进行缓存,防止数据丢失。Channel可以同时处理多个source和多个sink的操作。Flume中内置了两种Channel:Memory Channel 是内存中的队列。Memory Channel 在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么 Memory Channel 就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。File Channel 将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Flume的拓扑结构
前面我们学习了Flume的基础架构,我们知道了一台Flume是如何工作的,接下来我们来学习多台Flume组成集群是怎样配合工作的。
Flume的拓扑分为三种情况,分别是串联、复制与多路复用、聚合。
串联
串联是将多台Flume进行顺序连接,后一台Flume的source对接前一台Flume的sink,其中数据使用Avro格式传输。但在此模式下,随着串联节点的增多,数据传输的效率会有一定程度的降低。而且,串联模式下,链路上的一台Flume发生故障则会导致整个集群故障,因此不建议串联过多的Flume节点。

复制和多路复用
复制和多路复用是将事件流多路复用一个或多个目的地。比如说,只有一个source,但可有配置多个channel,同样也配置多个sink,一份数据可以既sink到文件系统,也sink到另一个agent的source,或其他什么地方。
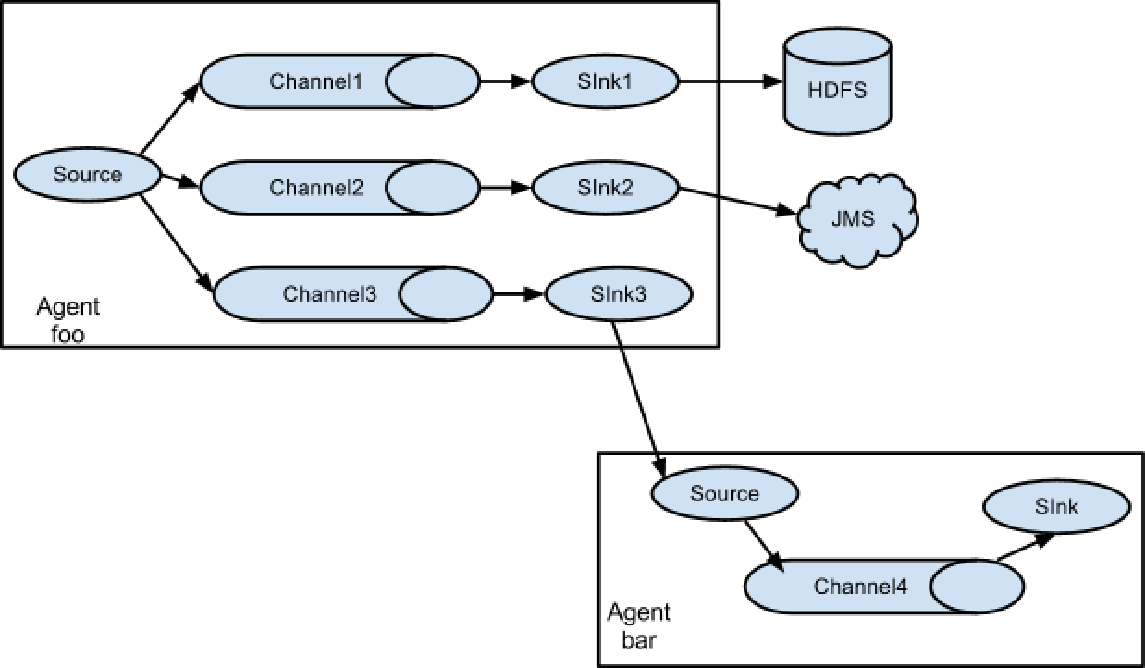
聚合
聚合是企业中常用的拓扑模式。聚合的作用是将多台机器的flume的数据聚合到一台flume中。常见的场景是,集群中有上百台机器,要收集每台机器中业务系统的日志写入到HDFS或HBASE中再进行数据分析,使用flume的聚合模式就能够很好的解决这个问题。统一由一台或Flume接收,并将数据写入到HDFS。
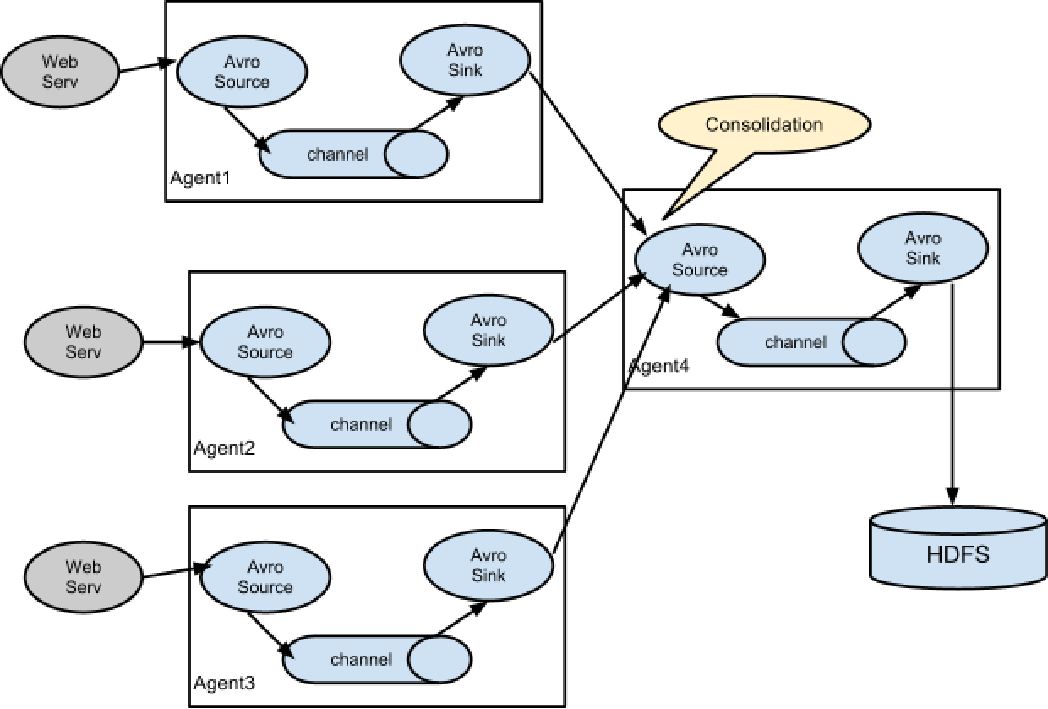
Flume的内部原理
通过前面的学习,我们对Flume有了一个宏观的认识,接下来,我们对Flume的内部原理进行学习。首先我们先学习两个重要的组件:Channel Selector,Sink Processor。
重要组件
Channel Selector
Channel Selector是通道选择器,从名字可以看出,是用来选择channel的,决定了Event将要发往哪个channel。Channel Selector有两种类型,分别是Replication(复制)与Multiplexing(多路复用):Replication Selector会将同一个Event发往所有的Channel,而Multiple Selector会根据相应的原则将不同的Event发往对应的Channel。这就实现了我们前面讲到的复制与多路复用的拓扑结构。
Sink Processor
Sink Processor作用于Sink group内的所有sink。这里有个新概念是Sink Group,Sink Group是将多个sink绑定为一组,用于实现负载均衡或故障转移。具体实现方法就要依赖于Sink Processor的两种不同类型:LoadBalanceingSinkProcessor,实现SinkGroup内的负载均衡,将数据轮询的传输到不同的sink;FailoverSinkProcessor,实现SinkGroup内的故障转移,当一个sink不可用时则会将数据传输到其他sink,以保证系统可用。还有一个是DefaultSinkProcessor,这是默认的processor,用于对应单个sink,在此不多赘述。
Flume事件处理流程
在了解了重要组件之后,我们对Flume对event处理的整个流程进行一次梳理。
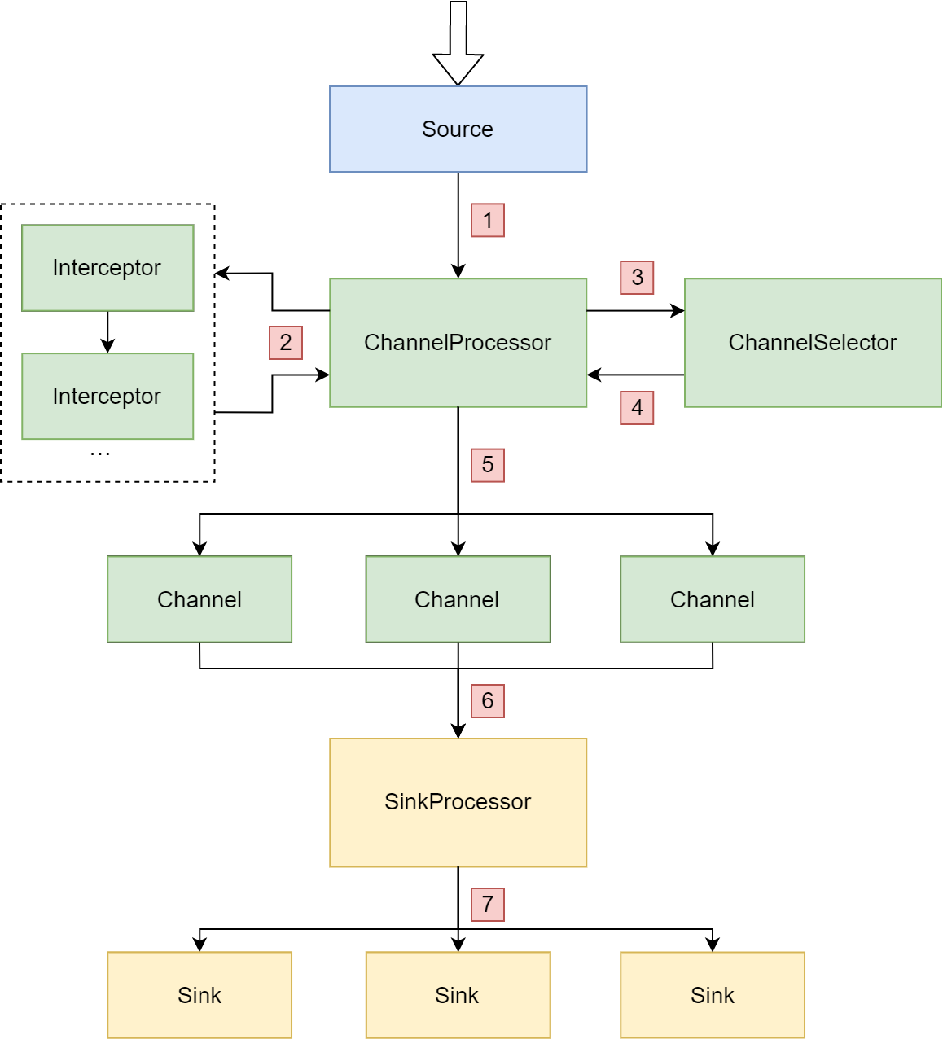
- 首先由source接收数据,数据传输给Channel Processor进行处理。
- Channel Processor将event传递给拦截器链进行过滤。这里有一个新概念叫拦截器链,首先我们要知道拦截器是什么。类似于Java中的拦截器,Flume的拦截器也是对数据进行一定规则的过滤,并且数据可以依次通过多个拦截器,因此成为拦截器链。拦截器会对event的header加入标记,以便后续组件使用。
- Event经过拦截器链的调用之后回到Channel Processor,Channel Processor将event传递给Channel Selector,由Selector根据不同Selector的类型进行Channel的选择。Multiplexing Selector将根据event header中的信息为依据对event进行处理。
- Channel Selector将选择后的event列表返回channel Processor。
- Channel Processor根据上述步骤返回的Channel列表,将event传递给对应的Channel。
- Channel将event传递给Sink Processor进行Sink的选择。
- Sink Process根据不同类型的Processor,执行不同的分发策略。此处若是LoadBalanceing则会轮询的向每个sink发送数据;若是Failover则会向一个节发送数据,若该节点发生故障,则会转移到其他节点。
Flume安装部署
下载安装包
首先我们来进入官网提供的下载地址http://archive.apache.org/dist/flume/
选择对应的版本,此处我们选择1.9.0版本,选择编译好的二进制包,apache-flume-1.9.0-bin.tar.gz进行下载。
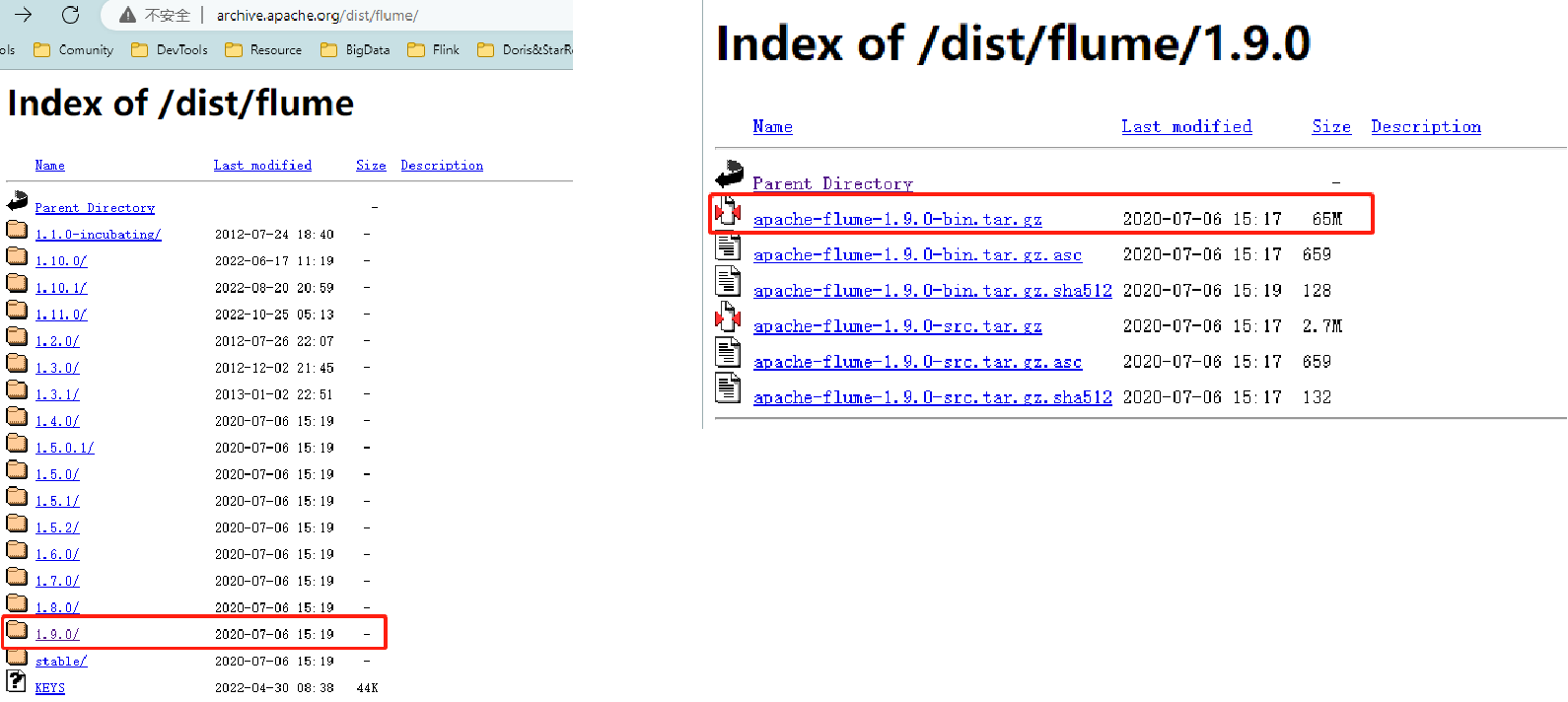
然后我们把tar包上传到服务器的指定目录,然后对其进行解压。使用tar -zxvf apache-flume-1.9.0-bin.tar.gz进行解压。
避免兼容性问题
解压完成后,我们为了避免与Hadoop 3.1.3的兼容性问题,我们将lib目录下的guava-11.0.2.jar包进行删除,这里我使用 mv lib/guava-11.0.2.jar lib/guava-11.0.2.jar.bak,其实这里并没有真正删除,而是给它修改了名字,当做删除。
到这里Flume的安装就结束了,还是很简单的。接下来我们通过一个简单的案例来测试一下我们的Flume是否已经正常,同时也通过这个案例了解Flume采集数据的基本配置。
Flume简单案例
本案例中,我们通过Flume监听HTTP日志,并将日志上传到HDFS。
首先,我们对整体流程进行梳理。
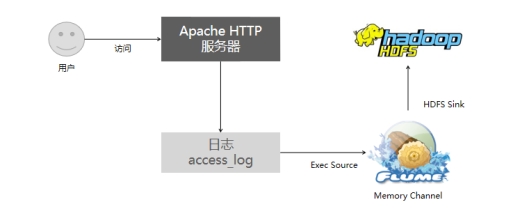
如图所示,用户访问HTTP服务器,服务器生成对应的access_log文件,并将日志写入该文件中。我们通过Flume,使用Exec Source进行对access_log文件监听,并且使用HDFS Sink,将数据写入到HDFS中。
Http服务器的安装
Apache HTTP 是一个开源 HTTP 服务器。通过对HTTP服务器的访问可以生成网络访问日志。
安装步骤:
-
首先通过yum安装httpd服务:
yum install -y httpd -
启动服务:
systemctl start httpd -
检查服务运行状态:
systemctl status httpd -
访问并查看日志:通过浏览器访问该服务器ip的80端口
-
查看日志:
tail -f /etc/httpd/logs/access_log
这里的access_log就是一会儿我们要监听的文件。
Flume的配置
-
在flume安装目录下新建job目录
-
在job目录中新建配置文件flume-file-hdfs.conf :
vim job/flume-file-hdfs.confflume-file-hdfs.conf.conf文件内容:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /etc/httpd/logs/access_log # Describe the sink** a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://namenode:9000/flume/%Y%m%d #上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = http_log_ #是否按照时间滚动文件夹 a1.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a1.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a1.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a1.sinks.k1.hdfs.rollInterval = 60 #设置每个文件的滚动大小 a1.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a1.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
配置详解
这里我们介绍一下配置文件中一些重要的配置含义:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
这里a1代表当前agent的名称,我可以根据自己的需要设置,但要注意,同时运行的多个任务不可以出现重名的情况。
分别将a1的source、sinks、channels设置为r1、k1、c1,同样,这也是自己定义的,在后面要对r1、k1、c1进行具体的配置。
source配置
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /etc/httpd/logs/access_log
此处对r1进行配置,r1是source,类型我们设置为exec,exec的具体配置我们可以通过官方文档进行了解:https://flume.apache.org/releases/content/1.11.0/FlumeUserGuide.html#exec-source
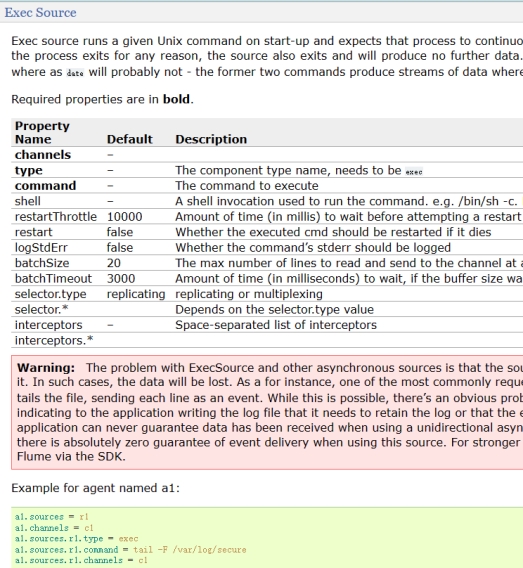
根据文档我们知道该source还需要两个配置,分别是command与channels,channel我们后面再进行配置,此处我们先配置command。Command用来配置要执行的命令,我们要持续的读取文件,所以此处我们配置tail -F /etc/httpd/logs/access_log。
Sink配置
接下来进行sink的配置,因为我们要上传到hdfs,所以此处k1的type设置为hdfs。通过官方文档https://flume.apache.org/releases/content/1.11.0/FlumeUserGuide.html#hdfs-sink
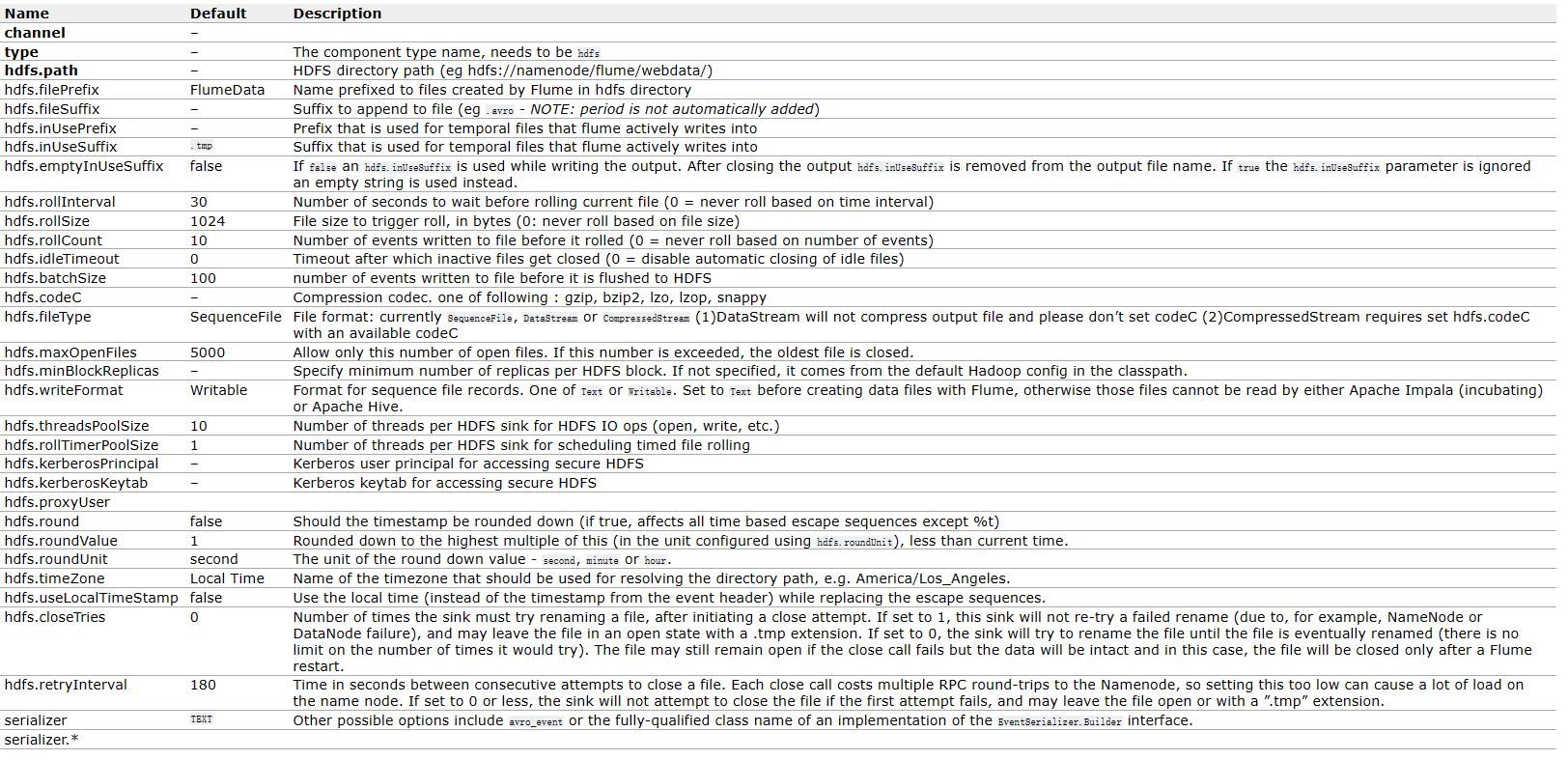
我们可以看到,必要的配置中,还有一个hdfs.path,就是用来指定文件上传到hdfs的路径。/flume/%Y%m%d/%H的意思是hdfs上/flume目录下,有一级年月日目录,下面还有一级小时目录,所以数据是每小时一个目录进行存储的。
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop-01:9000/flume/%Y%m%d/%H
这里hdfs的地址要换成自己的HDFS NameNode的地址与接口。
到此其实hdfs sink的最基本的配置已经完成了,接下来我们学习一些hdfs sink的调优配置:
#上传文件的前缀,我们指定由http_log_开头
a1.sinks.k1.hdfs.filePrefix = http_log_
接下来的三个配置为一组,hdfs.round是否按照时间滚动文件夹,如果为false,则我们刚才配置的文件目录/%Y%m%d/%H就会只在任务启动时创建一个,而不会滚动创建。
a1.sinks.k1.hdfs.round = true
下面两个配置决定了多久创建一个新目录,roundValue = 1,roundUnit = hour就是说1个小时创建一个。
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = hour
接下来这个配置是是否使用本地时间戳,这个配置如果设为false,则会使用event的header中的时间戳,因为我们前面设置了要按时间生成新目录,所以需要用到时间戳来作为时间。在这个任务中我们没有为event的header添加时间戳,所以我们必须让flume使用服务器的本地时间。
a1.sinks.k1.hdfs.useLocalTimeStamp = true
这个配置表示最多积攒多少个 Event 才 flush 到 HDFS 一次,并不是是一定达到这个值才进行写入,而是当数据量比较大使,最多达到100条数据就进行一次刷写。
a1.sinks.k1.hdfs.batchSize = 100
设置文件类型,可支持压缩,通过文档我们可知,输出到hdfs的数据可以支持SequenceFile, DataStream or CompressedStream三种格式,模式是SequenceFile,但数据会进行序列化,可观测性差,CompressedStream是压缩流,可以支持多种压缩格式,但为了更直观的查看数据,我们此处选择DataStream 数据流。
a1.sinks.k1.hdfs.fileType = DataStream
接下来三个配置也是一组,决定了什么时候新建一个数据文件。
多久生成一个新的文件,单位是秒,此处我们的配置就是规定每60秒生成一个文件
a1.sinks.k1.hdfs.rollInterval = 60
设置每个文件的滚动大小,单位是B,我们知道hdfs每个文件块的大小是128MB=134217728B,此处我们设置为134217700,不等到达文件块大小尺寸就创建新文件
a1.sinks.k1.hdfs.rollSize = 134217700
设置多少个event创建一个新文件,此处设置为0则表示文件的滚动与 Event 数量无关,上面的两个配置也一样,0表示与该项无关。
a1.sinks.k1.hdfs.rollCount = 0
上述的三个配置同时生效,但哪个先到达则会新建文件,不需要等待所有条件满足。
Channel配置
接下来配置channel,channel的类型我们设置为memory
a1.channels.c1.type = memory
通过文档
https://flume.apache.org/releases/content/1.11.0/FlumeUserGuide.html#memory-channel
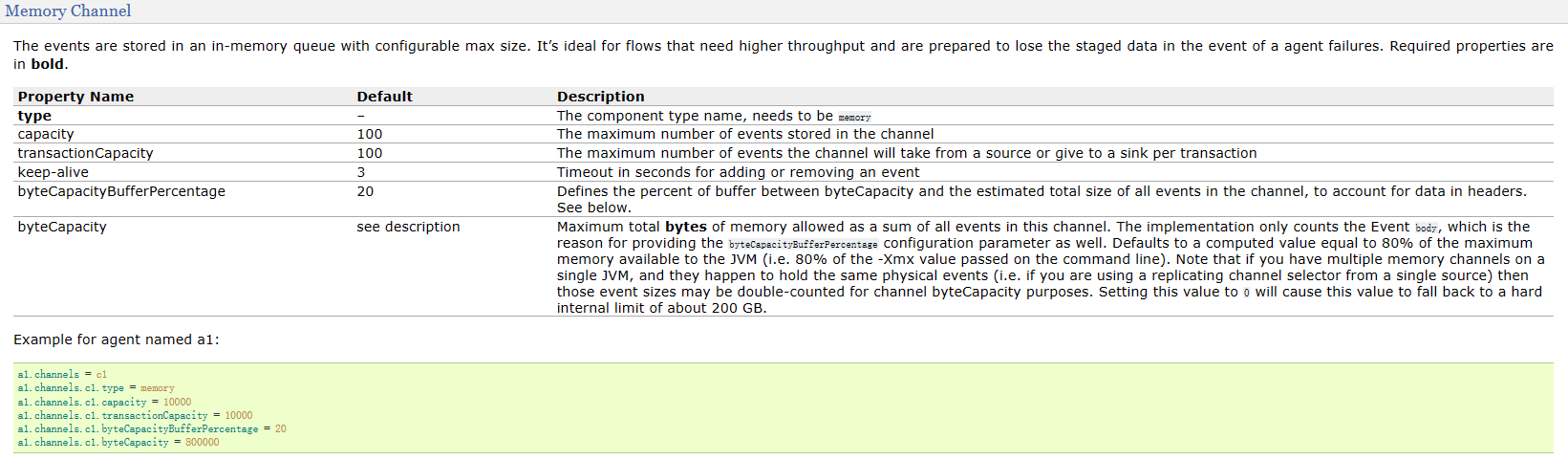
我们可以看到,memory有多个可选择的配置,此处我们配置两个比较重要的
Capacity是channel的容量,表示channel中能容纳的最大的event数,
a1.channels.c1.capacity = 1000
transactionCapacity 是channel事务的容量,在flume的source与sink直接,启用了事务机制,用来防止数据的丢失。事务容量决定了一次性从source写入channel的容量。
a1.channels.c1.transactionCapacity = 100
此处要注意,事务容量一定要小于等于channel的容量,如果事务容量更大,一次提供给channel的数据量大于channel能接受的数据量,这是不合理的。
组件绑定
最后是组件间的绑定
a1的sources——r1的channels绑定的c1
a1的sinks——k1的channel 也绑定的c1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
在完成配置文件的编写后,我们启动flume。
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-file-hdfs.conf
- –conf/:表示flume自身配置文件存储在目录,一般来说都是flume目录下的conf目录;
- –name表示agent的名称,对应配置文件里的 a1;
- –conf-file表示本次启动读取的配置文件的地址,此处我们制定为 job 目录下的 flume-file-hdfs.conf文件;
除此之外,还可以指定控制台日志输出日志级别:
- -Dflume.root.logger=INFO,console :-D 表示 flume 运行时动态修改 flume.root.logger参数属性值,并将控制台日志打印级别设置为 INFO 级别。日志级别包括:log、info、warn、error。
如果想让flume在后台运行,只需要使用nohup指令。
生成日志并查看
接下来我们访问服务器的80端口;
通过tail -f /etc/httpd/logs/access_log查看日志是否正常生成;
通过tail -f logs/flume.log查看flume是否报错;
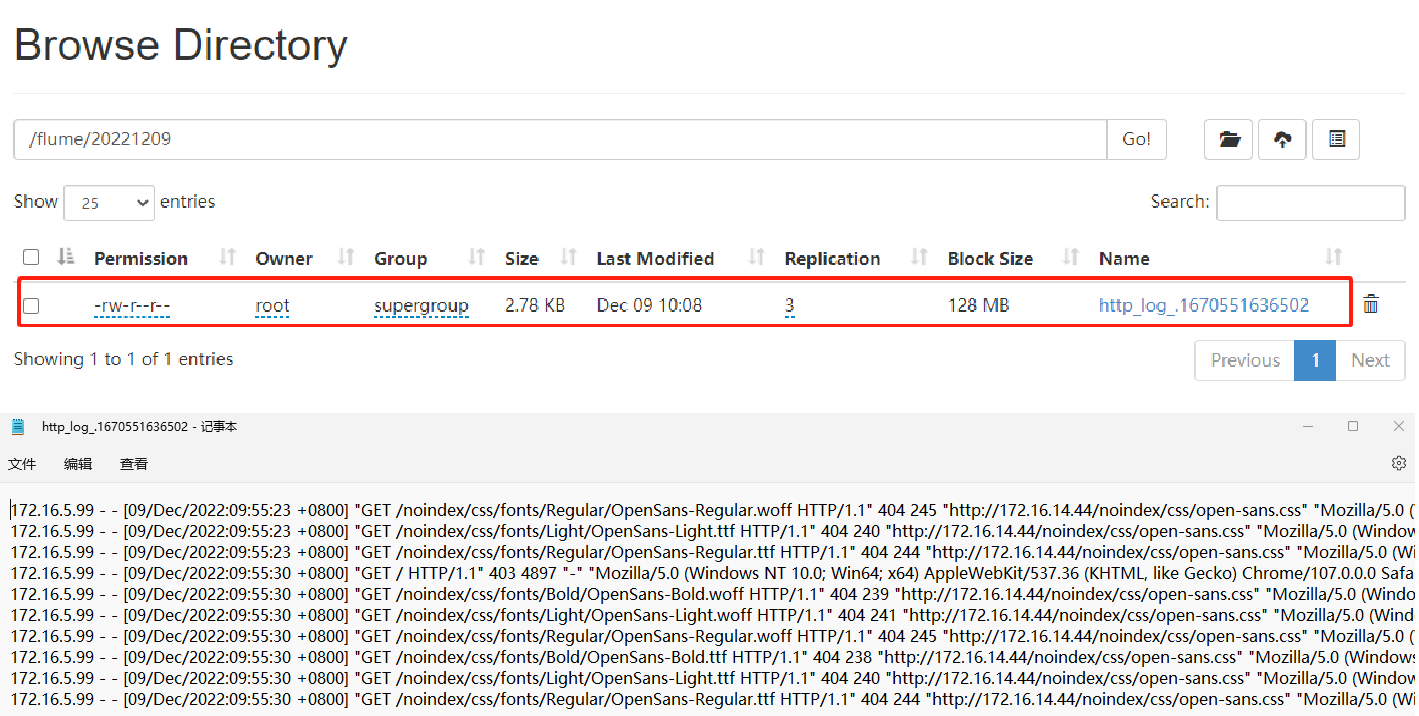
登录hdfs的web页面,找对对应时间的目录,查看生成的文件内容。
自定义拦截器开发
接下来我们来学习Flume的自定义拦截器开发。通过先前的学习,我们知道,Flume从source到channel之前会经过连接器链的过滤,Flume内部自带了一些拦截器,比如Timestamp Interceptor,Host Interceptor,Static Interceptor等。但如果我们想要实现一些定制化的需求,这时候就需要我们自定义拦截器的开发。
需求分析
需求:使用Flume监听access_log文件,上传到HDFS,并使用自定义拦截器对数据进行清洗,拦截非法日志数据。
在上个案例中,我们的正常数据是这样的:

我们假设ip地址不正确的时候为非法数据,我们要做的就是把ip地址不正确的数据过滤掉。其实这里这种::1 的ip地址也不是非法的ip,这是ipv6的环回地址,这里我们把它当做非法数据,方便我们举例。
对于source、sink与channel,我们延续之前的策略,不做修改。
自定义拦截器开发
-
首先在idea中创建一个maven项目,这里我命名为
interceptor-clean; -
在pom.xml文件中加入flume依赖:
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
-
创建目录
fun.coolcode.flume,这里可以自定义; -
在flume目录下创建一个类,这里我将其命名为
MyInterceptor;
实现Interceptor接口
该类实现flume的Interceptor接口:
public class MyInterceptor implements Interceptor;
我们可以看到接口中有:
initialize()intercept(Event event)intercept(List<Event> list)close()
其中initialize()、close()两个方法分别在拦截器的开始和结束时调用,只调用一次。我们要重点关注的是intercept(Event event)、intercept(List<Event> list)两个方法,这两个方法一个是在采集到单条数据时调用,一个是在采集到多条数据时调用。
实现intercept(Event event)
首先我们来写intercept(Event event)中的逻辑。
我们先看看Event中都有什么,可以看到,Event中有getHeaders、setHeaders、getBody、setBody四个方法。此处我们要对数据进行过滤,因此我们要使用getBody方法。我们发现getBody返回的结果是一个字节数组。为了方便处理我们将其转化为字符串。
String bodyStr = new String(event.getBody());
通过对数据的观察我们得知,数据中的字段都是以空格分割的,因此我们使用split方法对数据进行切割,再取第一段数据就可以得到ip地址的字段。
String[] bodyArr = bodyStr.split(" ");
String ipAddress = bodyArr[0];
接下来我们要对ip地址是否合规进行判断,此处我们使用正则表达式进行匹配。为了方便,我这里找了一个别人写好的ip匹配的正则表达式:
([1-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5])(\.(\d|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5])){3}
对于这串表达式我们可以放在正则表达式可视化工具中进行处理:
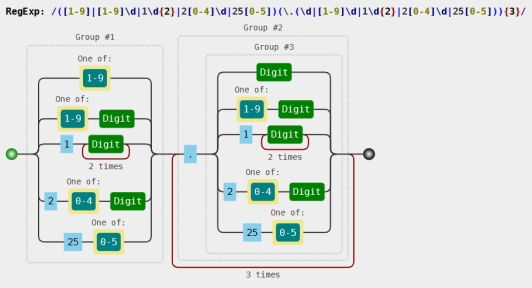
通过这张图就可以直观的看出,我们的匹配规则。关于正则表达式的内容在这里不多赘述。我们要更多的关注自定义拦截器的内容。
我们使用字符串的matches方法对数据进行正则匹配
boolean isIp = ipAddress.matches("([1-9]|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])(\\.(\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])){3}");
我们看到,返回的是个布尔类型,isIp为true表示数据中的ip符合规则,反之则不符合。因此我们可以通过if判断isIp的值,若isIp为false,则返回null,反之则返回event。
if (!isIp) {
return null;
}
到这里我们便完成了单个event的拦截器开发,
实现intercept(List<Event> list)
那么对于多个event的拦截器,其实就是把List
首先,我们定义一个ArrayList集合,用来接收返回结果:
List<Event> result = new ArrayList<>();
然后我们对入参的List
for (Event event : list) {
}
在这个循环中,每一次我们都要调用intercept(event)方法,并且将返回的结果进行判断,如果为null则说明是非法数据,不进行处理,如果返回不为null,则说明是合法数据,插入到result集合中:
for (Event event : list) {
Event event1 = intercept(event);
if (event1 != null) {
result.add(event1);
}
}
最后,将result集合返回。
实现Builder接口
完成拦截器的逻辑后,我们还需要编写一个Builder来帮我进行拦截器的构建。
创建一个静态内部类,就叫Builder,并且实现flume.interceptor的Builder接口:
public static class Builder implements Interceptor.Builder
实现该接口会发现重写了两个方法build和configure,build用来构建拦截器,configure用来读配置文件。这里我们在build方法中返回一个自定义interceptor对象即可:
public Interceptor build() {
return new MyInterceptor();
}
完整代码
public class MyInterceptor implements Interceptor {
@Override
public void initialize() {
}
/**
* 当拦截到单个Event的时候调用
*
* @param event 这个被拦截的Event
* @return 这个拦截器发送出去的Event
*/
@Override
public Event intercept(Event event) {
// ::1 - - [16/Dec/2022:15:19:24 +0800] "OPTIONS * HTTP/1.0" 200 - "-" "Apache/2.4.6 (CentOS) (internal dummy connection)"
byte[] body = event.getBody();
String bodyStr = new String(event.getBody());
String[] bodyArr = bodyStr.split(" ");
String ipAddress = bodyArr[0];
// ip地址不以数字开头的做标记
boolean isIp = ipAddress.matches("([1-9]|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])(\\.(\\d|[1-9]\\d|1\\d{2}|2[0-4]\\d|25[0-5])){3}");
if (!isIp) {
return null;
}
return event;
}
/**
* 批量拦截到Event
*
* @param list 存储Event的集合
* @return 处理之后的Event集合
*/
@Override
public List<Event> intercept(List<Event> list) {
List<Event> result = new ArrayList<>();
for (Event event : list) {
Event event1 = intercept(event);
if (event1 != null) {
result.add(event1);
}
}
return result;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new MyInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
编译并上传jar包
代码开发完成后我们进行打包上传,在idea中使用package命令进行打包,将生成的target目录中的jar包拷贝出来并上传到flume的lib目录中。
配置拦截器
拷贝上一个案例的配置文件
cp job/flume-file-hdfs.conf job/custom-interceptor.conf
编辑custom-interceptor.conf,新增两行配置:
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = fun.coolcode.flume.MyInterceptor$Builder
该配置的作用是拦截器绑定i1,i1的type指向拦截器引用路径的Builder。
完整Flume任务配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /etc/httpd/logs/access_log
# 拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = fun.coolcode.flume.MyInterceptor$Builder
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop-01:9000/flume/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a1.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a1.sinks.k1.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
测试
接下来我们启动flume:
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/custom-interceptor.conf
通过浏览器访问服务器的80端口,产生浏览日志。
通过hdfs的页面在对应时间的目录下查看生成的数据文件。
我们手动插入一条非法数据到access_log文件中:
echo ::1 - - [16/Dec/2022:21:42:26 +0800] "GET /noindex/css/fonts/Regular/OpenSans-Regular.ttf HTTP/1.1" 404 244 "http://172.16.14.43/noindex/css/open-sans.css" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46" > /etc/httpd/logs/access_log
再次查看hdfs中的文件,我们发现非法数据没有写入,说明拦截器过滤非法数据成功。
为了加以证明,我们再手动插入一条特殊的合法数据,ip为1.2.3.4:
echo 1.2.3.4 - - [16/Dec/2022:21:42:26 +0800] "GET /noindex/css/fonts/Regular/OpenSans-Regular.ttf HTTP/1.1" 404 244 "http://172.16.14.43/noindex/css/open-sans.css" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46" > /etc/httpd/logs/access_log
此时再查看hdfs中的文件,我们发现正常数据成功上传,说明拦截器对合法数据没有影响。
Flume使用TailDirSource监控多文件上传
前面我们使用exec source进行了文件的监听,但如果我们想对多个文件同时进行监听那么exec source显然是不能够满足需求的。
不同source对比
回忆一下我们之前学过的不同source,和文件相关的source除了exec还有Spooldir和TailDir。
- Exec source 适用于监控一个实时追加的文件,不能实现断点续传;
- Spooldir Source适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;
- Taildir Source适合用于监听多个实时追加的文件,并且能够实现断点续传。
接下来我们就使用TailDir来实现一个需求:实时监听整个目录下多个文件的追加,并上传至 HDFS。
对于本需求,channel与sink和之前保持不变,source由exec变成了TailDir。
Flume配置
为此我们先创建一个input目录,用来存放要监听的文件:
mkdir /data/input
还是拷贝一下第一个案例的配置文件:
cp job/flume-file-hdfs.conf job/custom-interceptor.conf
此处要修改几个地方:
-
source的type要改为TAILDIR
a1.sources.r1.type = TAILDIR -
positionFile是用来记录每个tailing文件的inode、绝对路径和最后位置的文件,默认是在
~/.flume/taildir_position.json,此处我们可以修改为/data/flume_data/taildir_position.json。别忘了要在启动之前创建对应的目录。a1.sources.r1.positionFile = /data/flume_data/tail_dir.json -
filegroups对应下面声明的文件组名称,此处我们设置两个分别为f1 f2
a1.sources.r1.filegroups = f1 f2我们设置了f1与f2两个文件组,接下来我们要对这两个文件组进行配置:
f1用来监听所有文件名中带有“log”的文件,f2用来监听所有文件名中带有“error”的文件,此处可以用正则表达式进行匹配:
a1.sources.r1.filegroups.f1 = /data/input/.*log.* a1.sources.r1.filegroups.f2 = /data/input/.*error.*.*在正则中表示匹配所有。 -
此处我们修改一下文件的前缀,用来和以前的数据做区分:
a1.sinks.k1.hdfs.filePrefix = upload-
完整Flume任务配置
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /data/flume_data/tail_dir.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /data/input/.*log.*
a1.sources.r1.filegroups.f2 = /data/input/.*error.*
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://namenode:8020/flume/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个 Event 才 flush 到 HDFS 一次
a1.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是 128M
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与 Event 数量无关
a1.sinks.k1.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置完成,别忘了创建flume_data目录:
mkdir /data/flume_data
测试
接下来我们启动flume:
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-taildir-hdfs.conf
现在向文件中写入数据测试:
我们先往一个叫log01.txt的文件中写入一条数据:
echo log01 >> /data/input/log01.txt
打开hdfs对应的路径下的文件,看到该条数据已经插入,然后我们向第二个log文件中写入数据:
echo log02 >> /data/input/log02.txt
再次打开hdfs对应的路径下的文件,看到该条数据也已经插入,说明f1文件组已经生效。接下来我们测试向error文件写入数据:
echo error01 >> /data/input/error01.txt
打开hdfs对于路径下的文件,发现error01数据也已经写入,f2文件组也生效。