

正排索引与倒排索引
正排索引与倒排索引都是搜索系统中的数据结构。要解释什么是倒排索引之前,首先我们要了解什么是正排索引。
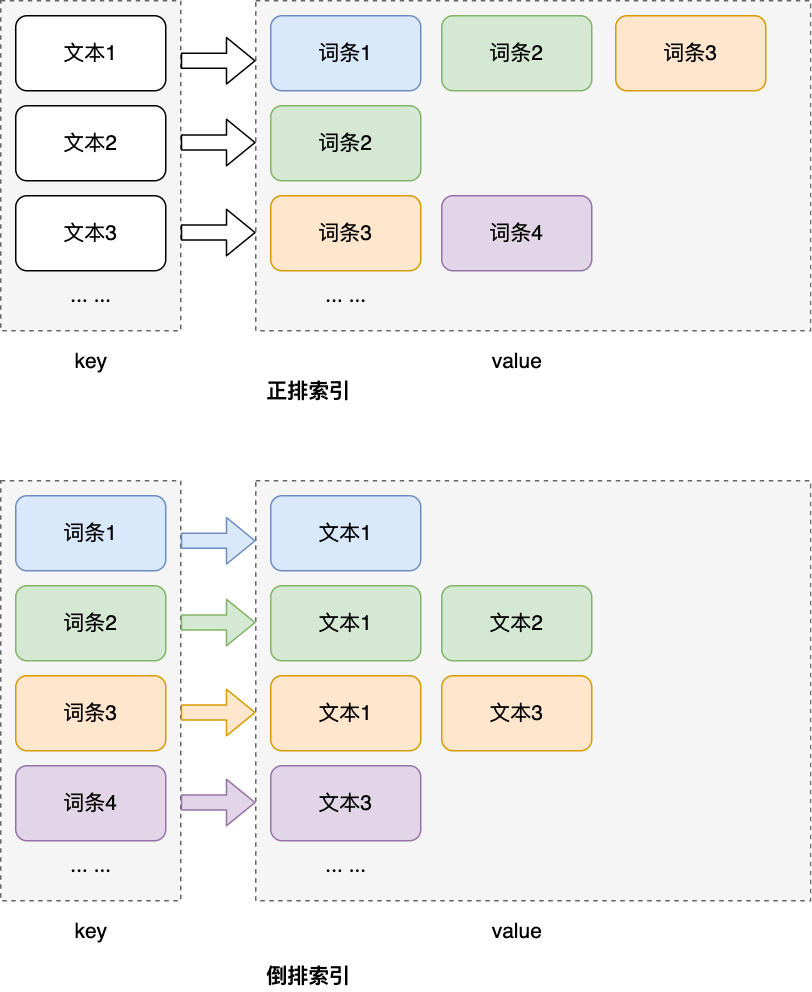
所谓正排索引,就是以文本为key,以分词的列表为value,通过检索文本信息来找到对应的分词列表。然而在实际进行搜索时所需要的结果恰恰与之相反,即以分词列表为key,检索包含该词条的文本,这种结构即为倒排索引。
ES中倒排索引机制
在ES的倒排索引机制中有四个重要的名词:Term、Term Dictionary、Term Index、Posting List。
-
Term(词条):词条是索引里面最小的存储和查询单元。一段文本经过分析器分析以后就会输出一串词条。一般来说英文语境中词条是一个单词,中文语境中一个词条是分词后的一个词组。
此处涉及到分词器,分词器的作用是将一段文字分解为若干个词组,不同的分词器使用的分词算法不同,得到的分词结果也不同。
-
Term Dictionary(词典):词典是词条的集合,顾名思义,词典中维护的是Term。词典一般是由文本集合中出现过的所有词条所组成的集合。
-
Term Index(词条索引):由于词典中维护着文本中所有的词条,为了在其中更快的找到某个词条,我们为词条建立索引。通过压缩算法,词条索引的大小只有所有词条的几十分之一,因此词条索引可以存储在内存中,因此可以提供更快的查找速度。
-
Posting List(倒排表):倒排表记录的是词条出现在哪些文档里,以及出现的位置和频率等信息。倒排表中的每条记录称为一个倒排项(posting)。
将以上概念类比到词典中,Term相当于词典中的词语,Term Dictionary相当于词典本身,Term Index相当于词典的目录。
举个栗子,假设现在我们输入系统多段文本,经过分词器分词后得到以下词条:
- elastic
- flink
- hadoop
- kafka
- spark

我们使用ES进行全文搜索时,如图所示,系统首先会通过Term Index找到该Term在Term Dictionary中的位置,再通过倒排索引结构找到对应的Posting,从而定位到该词组在文本中的位置,完成一次搜索。
广告时间
腾讯云 Elasticsearch Service(ES)是基于开源引擎打造的云端全托管 ELK 服务,集成 X-Pack 特性、独有高性能自研内核、QQ 分词、集群巡检、一键升级等优势能力,引入极致性价比的腾讯自研星星海服务器。助您轻松管理和运维集群,高效构建日志分析、运维监控、信息检索、数据分析等业务。
【腾讯云】ElasticSearch新用户特惠,快速实现日志分析、应用搜索,首购低至4折

↑↑↑现在新用户免费试用30天,快点击上方连接开启试用吧。↑↑↑