

前期准备
进安装之前我们先对集群进行规划。我们知道,Zookeeper对于Kafka来说是十分重要的,Zookeeper负责Kafka集群的:Broker、Topic、Consumer的注册,Producer 和 Consumer 负载均衡以及维护 Partition 与 Consumer 的关系,记录消息消费的进度等工作,因此我们在部署Kafka之前要先对Zookeeper进行部署。
Zookeeper也是分布式架构,最少需要三台机器组成集群,且节点必须为奇数,因为要通过节点间互相选举选择leader节点,如果集群是偶数节点,则可能出现平票的情况,则不能正常进行选主操作。
此处我们将三台集群都部署zookeeper。Kafka集群虽然没有对节点数进行要求,但broker的数量能够影响topic的分区与副本数设置,从而影响集群的吞吐量,为此我们也设置为三台。
| hadoop-01 | hadoop-02 | hadoop-03 | |
|---|---|---|---|
| Zookeeper | √ | √ | √ |
| Kafka | √ | √ | √ |
Zookeeper主要由Java语言开发,Kafka由Scala语言开发。Scala语言是一种类Java语言,也运行在Java的JVM虚拟机上,它集成了面向对象与函数式编程思想,语言相较Java更加简洁。Scala在大数据领域有着比较广泛的使用,有名的计算引擎Spark就是由Scala开发。因此,我们要运行Zookeeper与Kafka需要我们机器上有JVM虚拟机,此处我们选择jdk1.8环境。
Zookeeper安装
我们首先进行Zookeeper的安装。
安装包准备
我们先打开Zookeeper官方下载页面,https://zookeeper.apache.org/releases.html
此次我们选择3.5.10版本进行下载。

下载完成后,将安装包上传至服务器指定目录并进行解压:
tar -zxvf apache-zookeeper-3.5.10-bin.tar.gz
解压完成后,我们为zookeeper创建数据与日志目录
mkdir -p /data/apache-zookeeper-3.5.10-bin/data
mkdir -p /data/apache-zookeeper-3.5.10-bin/logs
修改Zookeeper配置
接下来我们移动到zookeeper的配置目录
cd /data/apache-zookeeper-3.5.10-bin/conf
复制配置文件zoo_sample.cfg为zoo.cfg并进行编辑
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
我们需要修改一下数据存放目录,就是我们刚才创建的data目录
dataDir=/data/apache-zookeeper-3.5.10-bin/data
然后新增日志目录
dataLogDir=/data/apache-zookeeper-3.5.10-bin/logs
在文件的最后新增集群信息:
server.1=172.16.14.43:2888:3888
server.2=172.16.14.44:2888:3888
server.3=172.16.14.45:2888:3888
分发安装包
保存好配置文件后我们将安装包分发到其他两个节点上。
先移动到zookeeper安装目录的上层目录
scp -r apache-zookeeper-3.5.10-bin hadoop-02:$PWD
scp -r apache-zookeeper-3.5.10-bin hadoop-03:$PWD
为每个节点设置myid
分发完成后我们要为各节点设置自己的myid,我们将节点的id写入到zookeeper data目录下的myid文件中即可。
节点1:
echo "1" > /data/apache-zookeeper-3.5.10-bin/data/myid
节点2:
echo "2" >/data/apache-zookeeper-3.5.10-bin/data/myid
节点3:
echo "3" > /data/apache-zookeeper-3.5.10-bin/data/myid
启动Zookeeper集群
这样我们就完成了zookeeper的部署,接下来我们启动集群。
在三台机器上都要启动Zookeeper服务
bin/zkServer.sh start
通过status命令查看集群状态
bin/zkServer.sh status
此时我们发现只有一台的角色为leader。
我们对zookeeper进行连接测试
bin/zkCli.sh -server 127.0.0.1:2181
连接成功后执行ls /
因为集群是新创建的,里面还没有数据,但集群已经正常可用。
Kafka的安装
完成Zookeeper的安装后我们就可以进行kafka的安装。
安装包准备
与之前一样,我们进入kafka官网进行kafka安装包的下载:https://kafka.apache.org/downloads.html
可以看到,kafka的版本迭代还是比较快的,已经到了3.x版本,但目前企业使用比较多的还是1.x与2.x版本,甚至有写企业还在使用0.x版本。但好在kafka不同版本间使用差别不太大,这里我们选择2.x的最后一个版本2.8.2进行安装。为了节约时间,我们依然对安装包进行了提前下载。
完成下载后,我们将安装包上传至服务器,并对tar包进行解压
tar -zxvf kafka_2.12-2.8.2.tgz
解压完成后我们在kafka安装目录下为期创建日志目录,与之前我们使用的flume、zookeeper等组件不同,kafka的日志并不单单是指系统日志,而是用来存储消息的日志,我们知道kafka中一个主题有多个分区,一个分区又多个副本,而每个副本都会对应一个log日志进行存储,所以说日志是kafka中消息在磁盘上的存储形式。
cd kafka_2.12-2.8.2/
mkdir logs
修改Kafka配置
接下来我们来看一下kafka的配置文件
vim config/server.properties
broker.id=0 #这是broker的全局唯一编号,不能重复,我们要为不同机器上的broker设置不同的id
delete.topic.enable=true #删除topic功能使能,如果不开启则不能对topic进行删除
num.network.threads=3 #处理网络请求的线程数量
num.io.threads=8 #用来处理磁盘IO的现成数量
socket.send.buffer.bytes=102400 #发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #请求套接字的缓冲区大小
log.dirs=/data/kafka_2.12-2.8.2/logs #kafka运行日志存放的路径,这里我们改为刚才我们创建的目录
num.partitions=1 #topic在当前broker上的分区个数,此处为全局变量,默认就是1,后续可以在创建topic时手动指定分区数
num.recovery.threads.per.data.dir=1 #用来恢复和清理data下数据的线程数量
log.retention.hours=168 #segment文件保留的最长时间,超时将被删除
zookeeper.connect=hadoop-01:2181,hadoop-02:2181,hadoop-03:2181 #配置连接Zookeeper集群地址,配置我们zookeeper集群的2181端口
这里我们多数配置沿用默认配置即可,但要注意修改三个地方,
- 开启topic删除功能;
- 修改log目录为我们指定的目录;
- zookeeper集群地址修改为我们搭建的zookeeper地址。
分发安装包
修改好配置文件后,将安装包分发到其余节点。先移动到kafka安装目录的上级目录
scp -r kafka_2.12-2.8.2 hadoop-01:$PWD
scp -r kafka_2.12-2.8.2 hadoop-02:$PWD
为每个节点设置brokerid
分别修改其余两台机器的broker.id
vim config/server.properties
将三台机器的broker.id分别设置为
-
broker.id=0 -
broker.id=1 -
broker.id=2broker.id不得重复
设置环境变量
为了方便使用,我们可以将kafka的路径配置到环境变量中
vim /etc/profile
添加环境变量:
#KAFKA_HOME
export KAFKA_HOME=/data/kafka_2.12-2.8.2
export PATH=$PATH:$KAFKA_HOME/bin
刷新环境变量:
source /etc/profile
配置环境变量的目的是可以在机器的任何目录下执行kafka bin目录下的脚本,这不是必要的。
启动kafka集群
三台机器配置完成后,我们启动kafka集群,三台机器都要启动
cd /data/kafka_2.12-2.8.2
bin/kafka-server-start.sh -daemon config/server.properties
其中-daemon表示以后台常驻方式启动,否则窗口关闭后kafka进程会被杀死。
启动完成后使用jps查看kafka进程。
如果要停止集群,则需要在集群每台机器上都执行kafka-server-stop.sh stop指令,此处我们不做演示。
Kafka基本命令
前面我们对Kafka集群进行了部署,接下来我们学习一些Kafka的基本命令。我们可以先到kafka的bin目录下看一看都有哪些操作脚本可供我们使用。
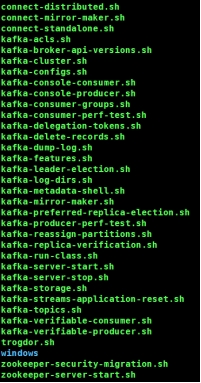
我们可以看到这里有我们刚才提到的服务启停用的kafka-server-start/stop脚本,有kafka-topic顾名思义这是与topic操作相关的,有kafka-console-producer/consumer,很明显这是kafka的控制台客户端的生产者和消费者,还有kafka-consumer-groups,这是后面我讲到操作消费者组要用到的脚本。接下来我们具体来看看这些脚本是如何使用的。
topic相关命令
我们知道kafka中消息都是以topic的形式进行存储、传输的,topic在整个kafka集群中是十分重要的。要操作topic,我们需要刚才提到的kafka-topic脚本。
创建topic
我们要让kafka传输数据,那么我们要先创建一个topic
kafka-topics.sh --bootstrap-server hadoop-01:9092 --create --replication-factor 1 --partitions 1 --topic test-topic
这里–bootstrap-server后面跟kafka集群的信息,可以配一个节点也可以配整个集群,效果都是一样的,早期的kafka版本中,此处要使用–zookeeper参数,后期版本中直接使用–bootstrap-server参数传入kafka自身集群地址即可;
-
--create就是表示我们是要创建topic; -
--replication-factor和--partitions表示该topic的副本数和分区数,此处我们都设为1,即1分区1副本; -
--topic指明topic的名称,此处我们给topic取名为test-topic。
查看当前集群中的所有topic
完成topic的创建后,我们使用list指令查看集群中所有topic的列表
kafka-topics.sh --bootstrap-server hadoop-01:9092 --list
我们看到我们刚刚创建的test-topic已经创建。
查看某个topic的具体信息
当我们想要查看一个topic的具体信息时,我们可以通过describe指令查看
kafka-topics.sh --bootstrap-server hadoop-01:9092 --describe --topic test-topic

其中PartitionCount: 1 ReplicationFactor: 1 就是说该topic共有1个分区1个副本;
Configs: segment.bytes,这是topic的段大小,超过这个大小会创建新的段。默认为1073741824字节,就是1GB;
下面的信息就是具体每个分区的信息,此处Partition: 0 Leader: 0 Replicas: 0 Isr: 0,说明只有一个0分区,且该分区的Leader与Replicas副本都在0号broker上。
Isr的全程是In-Sync Replicas ,是一个副本的列表,里面存储的都是能跟leader 数据一致的副本,也就是可以备选成为Leader的副本。
此处Isr显示的是已经完成同步的副本所在的broker。
增加topic分区数
我们在创建topic的时候指定了topic的分区数,但随着业务的变化,数据量可能会超过之前的预期,此时可能需要通过调整分区数来适应新的数据量。
kafka-topics.sh --bootstrap-server hadoop-01:9092 --alter --topic test-topic --partitions 3
--alter表示对topic进行修改--partitions表示修改后的分区数。
这样我们就把该topic从1个分区拓展为了3个分区。这里一定要注意,分区数只能增加不能减少。
在修改完分区数之后,我们再次使用上面学过的describe命令查看该topic的详情
kafka-topics.sh --bootstrap-server hadoop-01:9092 --describe --topic test-topic

这样我们可以看,topic目前有三个分区,分别是分区0/1/2,三个分区每个分区各有1个副本在各自对应的节点上,Isr也是一样。
这里我们为了更好的理解kafka的副本分配,我们可以再创建一个3分区3副本的topic进行观察
kafka-topics.sh --bootstrap-server hadoop-01:9092 --create --replication-factor 3 --partitions 3 --topic test-topic2
kafka-topics.sh --bootstrap-server hadoop-01:9092 --describe --topic test-topic2

这里我们就可以看到,三个分区,每个分区有三个副本,副本会均匀的分配到每个broker,三个副本中,最前面的是leader节点,其他两个为follower节点。
删除topic
前面我们讲了创建topic,有创建就会有删除,若要删除topic要使用到delete指令
kafka-topics.sh --bootstrap-server hadoop-01:9092 --delete --topic test-topic2
这样topic就删除成功了。这里要注意,我们前面在kafka配置中添加了delete.topic.enable=true这一项,如果不添加则只是标记删除或者直接重启。
生产消费相关命令
完成topic创建之后,我们就可以向topic中添加数据。我们回忆一下前面学习的内容,kafka有生产者和消费者两个角色,生产者负责消息的产生,消费者负责消息的读取。我们先来看一下如何使用生产者客户端生产数据。
生产消息
生产消息我们要用到kafka-console-producer脚本,console就是控制台,这个脚本的作用就是能够让我们在控制台生产数据。
kafka-console-producer.sh --bootstrap-server hadoop-01:9092 --topic test-topic
与操作topic一样,需要指定bootstrap-server到我们的kafka集群。
进入生产界面后,我们就可以向这个topic中写入数据。
现在数据以及写入了,我们还需要一个消费者进行数据的读取。数据的消费有多种模式,可以从头开始消费,也可以从最新数据开始消费,也可以指定分区进行消费。我们先来看看如何从头开始消费。
从头消费topic
从头开始消费,会把当前topic中存储的消息都读出来,我们前面使用了console-producer脚本,这里要使用kafka-console-consumer脚本进行消费
kafka-console-consumer.sh --bootstrap-server hadoop-01:9092 --topic test-topic --from-beginning
要注意最后的参数–from-beginning,就是告诉kafka,我们要从最开始的位置消费。
通过消费该topic,我们可以看到前面我们生产的数据已经被消费者读取出来。
从最新消费topic
前面我们通过指定from-beginning让消费者从头开始消费数据,如果不加这个参数,kafka则会从最新开始数据开始消费
kafka-console-consumer.sh --bootstrap-server hadoop-01:9092 --topic test-topic
这时我们发现消费者没有消费到数据,这时因为最新时间我们没有产生数据。我们保持消费者不动,再使用生产者生产几条数据,这样我们发现,新产生的数据已经被消费者消费到。
指定分区消费topic
我们刚才讲到,kafka还能指定分区进行消费,只需要在消费命令后面加上--partition 参数,指定要消费哪个分区。
kafka-console-consumer.sh --bootstrap-server hadoop-01:9092 --topic test-topic --partition 0
此处我们消费0分区,然后我们再向该topic中写入数据,观察消费者情况,我们发现并不是每一条消息都被读出,这是因为我们只消费了partition0,而只有一部分数据落在partition0上,所以我们只消费到了一部分数据。指定分区消费可以帮助我们确定某个分区上的数据情况,排查特定分区的问题。
取指定条数数据
除了可以指定分区消费,我们还可以取指定条数数据消费,比如有些时候某个topic中数据量很大,我们只想取几条数据观察一下数据效果,此时我们就可以用–max-messages参数来指定消费条数。
kafka-console-consumer.sh --bootstrap-server hadoop-01:9092 --topic test-topic --from-beginning --max-messages 1
这里我们从头开始消费,因为历史数据比较多,然后我们指定--max-messages 1 ,我们就取1条数据。然后我们可以看到,只有一条数据被读出。
消费者组相关命令
前面我们学习kafka基础知识的时候学到过消费者组,我们说消费者组是由一个或多个消费者组成的组,一个消费者组共同消费一个topic。所以,在我们执行消费指令时,是可以指定消费者组的。
指定消费者组消费
消费者组不需要特意创建,在消费者进行消费时直接声明消费者组的名称即可。此处我们消费test-topic,使用-group参数指定消费者组,消费者组为test-group
kafka-console-consumer.sh --bootstrap-server hadoop-01:9092 --topic test-topic -group test-group
测试:
此时我们使用生产者向topic中写入数据。
kafka-console-producer.sh --bootstrap-server hadoop-01:9092 --topic test-topic
我们发现我们写入的数据都被消费者消费了,看起来似乎也没什么不一样。但我们知道,消费者组共同消费同一个topic,那么我们再启动一个消费者,指定一样的消费者组,我们再来看看效果。
kafka-console-consumer.sh --bootstrap-server hadoop-01:9092 --topic test-topic -group test-group
此时两个消费者均属于消费者组test-group,我们向topic中写入数据,我们发现只有一个消费者接收到了消息,多尝试几次,我们发现有些数据被消费者1消费了,有些被消费者2消费了,但他们不会同时消费到同一条消息,这就是消费者组的作用。
测试单播:
此时,我们再启动一个消费者来消费该topic,但他属于另一个消费者组,
kafka-console-consumer.sh --bootstrap-server hadoop-01:9092 --topic test-topic -group test-group2
现在我们继续向topic中写入数据,这时候我们就发现,新启动的消费者能够消费到所有数据,因为它在一个只有一个消费者的消费者组当中。这也是使用消费者组实现单播的具体方法。
展示所有消费者组
我们使用过消费者组后, 该消费者组就好被保留下来,我们通过kafka-consumer-groups脚本可以对消费者组进行操作。使用--list可以可查看集群中所有消费者组列表。
kafka-consumer-groups.sh --bootstrap-server hadoop-01:9092 --list
查看消费者组详情
与topic类似,我们可以通过--describe命令查看某个消费者组的具体信息。
kafka-consumer-groups.sh --bootstrap-server hadoop-01:9092 --group test-group --describe

可以看到该组对应的topic的每个分区的信息,共三个分区,该组在每个分区上消费的偏移量,每个分区上当前的生产数据偏移量以及两者的差距,LAG为0则说明该分区上的消息都被该组消费了。
删除消费者组
当我们不再需要某个消费者组时,可以将其删除,使用delete命令。
kafka-consumer-groups.sh --bootstrap-server hadoop-01:9092 --group test-group --delete
这样,我们再查看消费者组列表就会发现已经没有test-group了。
topic分区与副本数的规划
前面我们学习Kafka基本原理的时候讲到过kafka的分区数与副本数,在我们创建KafkaTopic时也是可以指定分区与副本数的。当然,分区数和副本数不是随便设置的,接下来我们学习一下如何合理的设置分区与副本数。
分区数规划
首先我们回忆一下topic分区的优点,Kafka中将topic分割成多个partition,每个分区可以分布到不同的机器上,分区可以实现高伸缩性,以及负载均衡,动态调节的能力。由于每个分区可以并发的进行数据的读写,多分区可以提高Kafka集群的吞吐量。
对于分区数的设置不同公司会有不同的方案,这里我们介绍一种常见的方案:
根据数据量划分
-
首先要对该topic中单位时间内的数据量进行测量,如果没有条件可以进行预估,将数据量记为t;
-
然后对单个分区上所能承载的生产数据量和消费数据量进行度量,生产数据量记为p,消费数据量记为c;
-
这里套用公式:
MAX( t/p , t/c),就是总吞吐量比上单分区生产数据量,总吞吐量比上单分区消费数据量,二者取最大的数,设为分区数。
举个栗子,假设我们每秒要处理100GB数据,那么t就是100,经过测试我们发现单个分区所能承载的生产数据量为10GB每秒记为p,单个分区所能承载的消费数据量为20GB每秒记为c,t/p=10,t/c=5,这里取最大,所以分区数设置为10个。
根据broker数量划分
这里还有一种根据broker数量设置分区的方法更为简单,直接将分区数设置为broker数量的2~3倍,这里根据数据量大小合理分配。
比如我们kafka集群有3个broker,我们可以把topic设置为6~9个分区。
副本数规划
我们回顾一下副本的作用,Kafka中将topic分割成多个分区,每个分区可以有多个副本。多个副本中只有一个是leader,leader负责对外提供数据读写。其他的follower副本作为leader副本的冗余备份,当leader副本出现问题时,从follower副本中选择一个成为一个新leader,继续对外提供服务。副本的作用就是进行冗余备份。
副本的作用决定了副本不需要太多。副本数的设置一般参照两个值
- 集群中broker的数量
- topic的分区数
为了保证副本的可用性,生产中我们副本数设置肯定是要大于1的,上限一般要看broker数量和分区数量,二者取更小的一个,公式:1 ≤ 副本数 ≤MIN(broker数量, 分区数)。
举个栗子,我们集群有三台broker,我们的topic有6个分区,这时候我们将副本数设置为3即可。